人工智能(AI)的快速發展離不開高質量的數據支撐,而數據處理服務作為AI數據服務的核心環節,扮演著至關重要的角色。本課件項目1-3聚焦于人工智能數據服務的基礎知識,特別是數據處理的概念、流程及其服務化應用。通過本文,我們將系統介紹數據處理在AI生態系統中的作用,幫助讀者構建扎實的理論基礎。
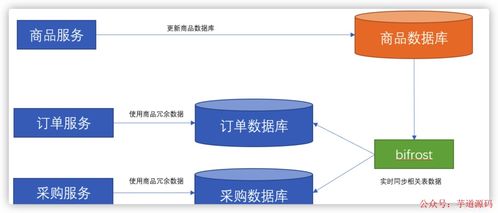
數據處理是指對原始數據進行采集、清理、轉換和整合的過程,旨在提升數據質量,使其適用于機器學習模型的訓練。在AI應用中,原始數據往往存在噪音、缺失值或不一致性問題,若不經過專業處理,可能導致模型性能下降。數據處理的關鍵步驟包括數據清洗(如去除重復記錄、填補缺失值)、數據標注(為無標簽數據添加類別信息)、數據增強(通過變換生成新樣本以擴展數據集)以及數據標準化(統一數據格式和范圍)。這些步驟不僅提高了數據的可用性,還增強了模型的泛化能力。
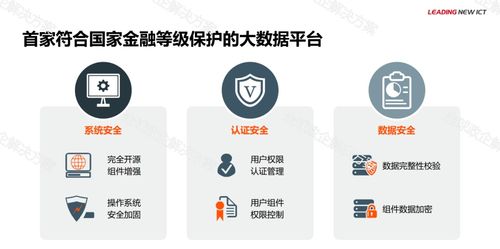
數據處理服務是將數據處理過程專業化和服務化的體現。隨著AI產業的成熟,許多企業選擇外包數據處理任務,以降低成本并提升效率。數據處理服務提供商通常提供定制化解決方案,例如圖像標注、文本分類、語音轉寫等,這些服務廣泛應用于自動駕駛、智能客服、醫療診斷等領域。通過云計算和分布式技術,數據處理服務能夠高效處理大規模數據集,確保數據的及時性和準確性。同時,服務提供商還注重數據安全和隱私保護,遵循相關法規如GDPR。
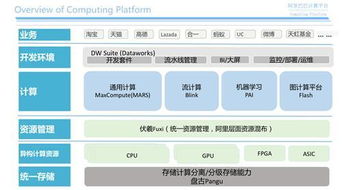
在項目實踐中,學習者應掌握數據處理的基本工具和技能,例如使用Python庫(如Pandas、NumPy)進行數據操作,或利用開源平臺(如TensorFlow、PyTorch)構建數據處理流水線。通過案例分析,例如一個圖像識別項目,從數據采集到標注、再到模型訓練的全過程,學習者可以深入理解數據處理服務在實際AI應用中的價值。隨著邊緣計算和實時數據處理的需求增長,數據處理服務將繼續演進,為人工智能的普及和創新提供堅實支撐。
數據處理是人工智能數據服務的基石,其服務化模式促進了AI技術的廣泛應用。通過本項目的學習,讀者將能夠識別數據處理的關鍵挑戰,并掌握相關實踐技能,為后續的AI項目打下堅實基礎。